点云网络:PointNet系列
PointNet框架
概述
问题定义
- 对点云信息直接做输入,输出类别
- 点云信息为一系列的点,包含位置、色彩、法向量等信息
- \{P_i\ |\ i=1,\cdots, n\}
- 只使用位置信息(x,y,z)
- 目标分类问题
- 输入:直接从形状中采样,或者从场景点云中预分割
- 输出:所有k个候选分类的打分
- 语义分割问题
- 输入:单个对象局部区域分割,或者三维场景中子体sub-volume
- 输出:为n个点和m个语义子类别输出n\times m个分数
框架图与点云特征
- 无序性:点云信息是一系列的无序点,点的输入顺序的不同应该输出相同的结果
- 相互作用:局部区域内的点云是非孤立的,存在相互作用,模型应该能够捕获局部特征信息
- 变换不变性:点云经过平移、旋转后输入,模型的输出结果不变
设计思路
无序性:Symmetry Function
- 存在三种思路解决点云无序性问题
- 将点按照特定方式排序
- 训练RNN,并用不同排序增广数据
- 使用对称函数,如加法、乘法、最大池化等
- 固定排序:高维空间下存在点扰动而无稳定排序
- 若在高纬空间下存在稳定排序,则必定存在一个从高维空间到一维空间的双射
- 降维时难以实现双射映射,无法使用固定排序,无普适性
- 训练RNN:对N个点的点云需要进行N!次不同排序的序列
- 已有文献指出了训练的RNN无法完全忽略掉顺序因素
- 点云数量庞大情况下,需要大量算力
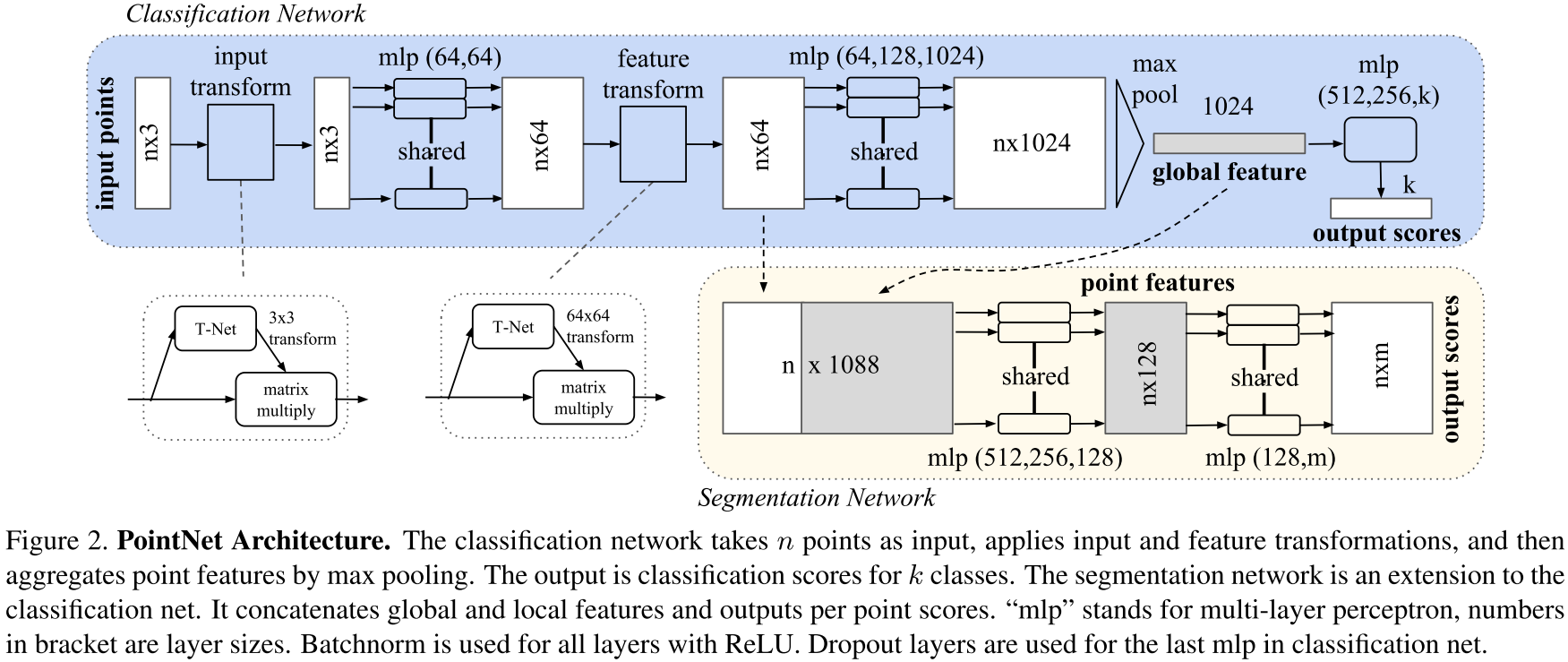
- 对称函数:采用对称函数实现消除点云输入顺序的影响
- 对称函数是指如加法、乘法操作,具有交换性
- 对输入的点云中的点首先使用MLP,h:\R^N\to \R^K
- MLP后采用最大池化操作,从而实现无序,g:\underbrace{\R^K\times\cdots\times\R^K}_n \to\R
f\bigg(\{x_1,\cdots,x_n\}\bigg)\approx g\bigg(h(x_1),\cdots,h(x_n)\bigg)
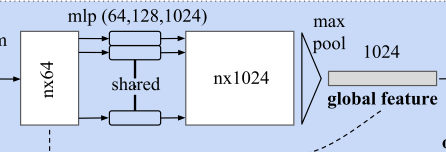
相互作用:Local and Global Information Aggregation
- 全局特征:Max Pooling输出为全局变量,可用于分类
- 局部特征:在做语义分割时,需要考虑到局部的几何特征信息
- 将全局特征concat至每个点上
- 局部几何特征:n\times 64
- 全局语义特征:1\times 1024
- 整合特征:n\times 1088
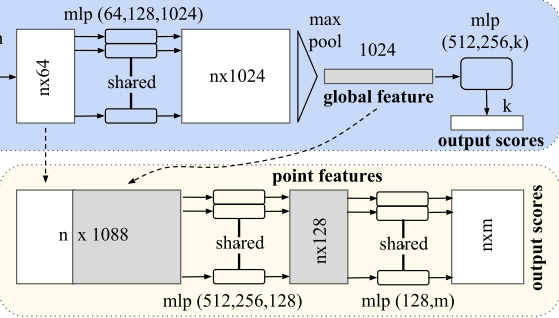
变换不变性:Joint Alignment Network
- 将所有的点云映射至同一空间内
- 训练一个T-Net用于预测仿射变换矩阵,并使其应用在输入上
- 训练一个T-Net用于对齐特征在特征空间上,保持特征的不变性
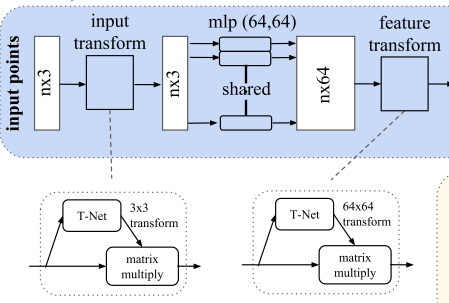
- T-Net可认为是一个PointNet,包括特征提取、最大池化、全连接层
- 在损失上添加正则化,使预测的仿射矩阵正交,从而优化的更加稳定
L_{reg}=\begin{Vmatrix}I-AA^T\end{Vmatrix}^2_F
代码学习
说明
- 本文学习的代码为PyTorch版本的,其Github链接如下:
pointnet_utils.py
-
定义了一些常用的模型
- STN3d:3维点云输入的T-Net网络,将输入点云映射至给定空间
- STNkd:k维特征的T-Net网络,将特征映射至给定空间
- PointNetEncoder:编码器
- 正则化项
-
STN3d类
- 先进行三次1\times 1的卷积,将输出通道升至1024
- 再进行最大池化,后进行三次线性层,压缩至9个特征
- 每层后跟随BN再Relu,最后加上一个3\times 3特征矩阵
# 创建一个 9 维的单位矩阵,并重复 batchsize 次
iden = torch.from_numpy(
np.array([1, 0, 0, 0, 1, 0, 0, 0, 1], dtype=np.float32)
).view(1, 9).repeat(batchsize, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
- STNkd类:基本类似,最后输出为k\times k个特征
- PointNetEncoder类
- 先用STN3d获取仿射矩阵并应用至输入样本x上
- 再用STNkd获取特征维度上的仿射矩阵并用于样本x上
- 将提取的局部特征保存为pointfeat变量,进一步做全局特征提取并最大池化
- concatenate后输出
# 正则化项
def feature_transform_reguliarzer(trans):
# 仿射矩阵的维度
d = trans.size()[1]
# 单位矩阵
I = torch.eye(d)[None, :, :]
if trans.is_cuda:
I = I.cuda()
# I - AA^T均值
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2, 1)) - I, dim=(1, 2)))
return loss
pointnet_cls.py
- PointNet用于分类,PointNetEncoder仅提取global\ feature
- 对提取得到的全局特征做三层MLP,从1024降至k维度
- 对k维度做log_softmax得到分类结果
- 计算损失时将正则加入其中
class get_loss(torch.nn.Module):
def __init__(self, mat_diff_loss_scale=0.001):
super(get_loss, self).__init__()
self.mat_diff_loss_scale = mat_diff_loss_scale
def forward(self, pred, target, trans_feat):
loss = F.nll_loss(pred, target)
mat_diff_loss = feature_transform_reguliarzer(trans_feat)
total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale
return total_loss
PointNet ++框架
概述
提升与变化
-
PointNet的问题
- 仅提取了单一点的特征,未利用点与点之间的局部特征(临近点之间的距离)
- CNN能够在多分辨率上逐步捕获不同尺度上的特征,在低水平上感受野较小而高水平上感受野较大
- 多尺度提取更好局部特征能够提高泛化性能
-
PointNet++分层采样度量空间中的点,解决两个主要问题
- 如何生成点云的划分
- 如何通过局部特征学习器抽取点云或局部的特征
-
使用PointNet做局部特征提取器
-
重叠区域点云的分割问题
- 每个分区定义为欧几里德空间中的邻域球,其参数包括质心位置和尺度
- 为了均匀地覆盖整个集合,通过最远点采样算法在输入点集合中选择质心
问题定义
- 在欧氏空间\R^n中定义\chi=(M,d),其中M\in\R^n为一系列的点组成的点云,d表示距离
- 点云构成的M在欧氏空间中密度并非均匀分布
- 期望学习得到一个映射函数f,其输入为\chi
- 当f的任务为分类时,输出为给定\chi的标签
- 当f的任务为语义分割时,输出为给定\chi中每一个点的标签
框架图与PointNet回顾
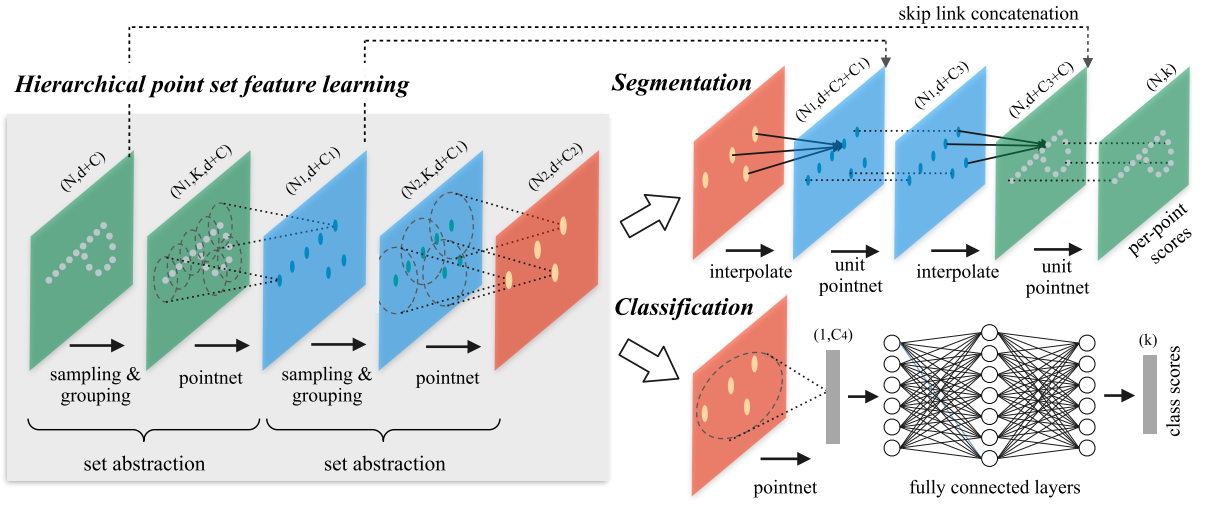
- 给定无序点云\{x_1, x_2, \cdots, x_n\},集合函数f:\chi\to \R将一系列的点映射至一个向量
- \gamma和h为给定的MLP网络,\max为最大池化层用作对称函数
- f不受输入点云的点序列排序影响,可逼近任意连续集合
f(\chi)=\gamma\bigg(\max_{i=1,\cdots, n} h(x_i)\bigg)
- PointNet缺乏在多尺度上捕捉局部特征的能力
设计思路
多层次点云特征学习
- 由一系列的集合抽象层(set abstraction)组成,每层上一组集合被处理,生成包含更少元素的新集合
- 输入:N\times(d+C),N个点,每个点包括d维度的坐标和C维度的特征
- 输出:N^{'}\times(d+C^{'}),下采样至N^{'}个点,每个点包括d维度的坐标和C^{'}维度的特征
- 每一层set abstraction由三个关键layer组成:
- 采样层Sampling Layer:从输入点云中采样一系列点集,表示局部区域的质心
- 分组层Grouping Layer:在质心周围寻找近邻,构造局部区域点集
- 特征提取层PointNet Layer:采用mini-PointNet,将局部区域的模式编码为特征向量
Sampling Layer
- 作用:下采样点云,采用迭代最远点采样(iterative Farthest Point Sampling, iFPS)提取局部的关键点(质心)
- FPS下采样:
- 给定输入点云\{x_1,x_2,\cdots,x_n\},规定下采样至m个点组成点云
- 随机选取一个点x_i,计算其余点到该点最远的一个点x_j,组成\{x_i, x_j\}
- 计算其余点到点集\{x_i, x_j\}最远的点x_k,组成\{x_i, x_j, x_k\}
- 重复迭代直至选出m个点
- 相比随机下采样,FPS更好覆盖整个采样空间
Grouping Layer
- 作用:采用Ball Query构建采样得到的质心形成的局部区域点集
- 输入:大小为N\times (d+C)的点云和N^{'}\times d的质心
- 输出:点云集合组N^{'}\times K\times (d+C),K为质心点的近邻数
- 每一组点云集合表征一个局部区域
- 每组以一个下采样质心为中心提取K个近邻
- 近邻个数K动态改变,在后续的PointNet层中可转为固定长度的局本部区域特征向量
- Ball Query近邻(三维的radius-nearest neighbor)
- 在三维空间中找寻给定质心为球心坐标,给定半径的球体内所有的点
- 实际实现中设置了K的上限
- 相比KNN,Ball Query保证了固定的区域尺度,使局部区域特征在空间上更具泛化性
- 在局部模式识别中常用Ball Query而非KNN
PointNet Layer
- 作用:特征编码,将输入的动态长度N^{'}\times K\times (d+C)的点云提取为固定长度的N\times (d+C^{'})
- 去中心化
- 局部区间内的点被转换至以局部质心为原点的局部坐标系内
- \hat x^{(j)}表示第j个质心,x_i^{(j)}表示第j个质心的邻域内的点
- x_i^{(j)}\leftarrow x_i^{(j)}-\hat x^{(j)}
- 使用PointNet做局部特征提取学习器
- 使用FPS下采样在做Ball Query近邻,从而考虑了点之间的距离关系
- 在各个邻域内做去中心化,完成获取局部点对点的特征
非均匀采样密度下的鲁棒特征学习
- 在不同区域内点云是非均匀的,导致点云提取工作存在挑战。在密集数据Dense Data中学习到的特征可能不能推广到稀疏采样区域Sparsely sampled regions。因此,为稀疏点云训练的模型可能无法识别细粒度的局部结构。
- 理想下进行密集检测点云,但在稀疏区域可能会导致局部模式被破坏。故而本文提出密度自适应PointNet层,称为PointNet++
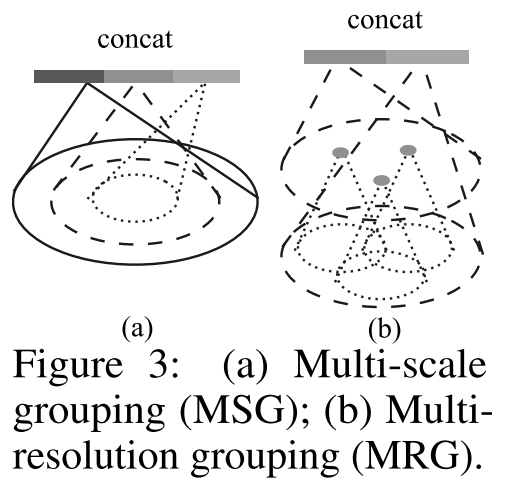
Multi-sacle grouping(MSG)
-
在不同尺度上使用Grouping Layers,再根据PointNets提取每个尺度上的特征,将不同尺度特征concat形成多尺度特征。
-
random input dropout随机输入dropout
- 对每个训练点云,均匀的从[0,p]中随机选取一个dropout ratio \theta
- 对点云中的每个点,根据\theta进行dropout
- 超参数p\le1,论文中设置为0.95,从而避免空集产生
-
MSG为每个质心在大规模邻域上运行local PointNet,在低层级中计算量庞大(K值较大)
Multi-resolution grouping(MRG)
- L_i层的局部区域特征由两个向量concat
- 图上左侧向量:根据set abstraction从L_{i-1}层汇总每个子区域的特征
- 图上右侧向量:使用单个PointNet直接处理原始点获取的特征
- 当局部密度较低时,第一个向量权重低于第二个,此时第一个向量内包含点稀疏,存在采样不足的情况
- 当局部密度较高时,第一个向量权重高于第二个,此时第一个向量提供更详细信息(高感受野)
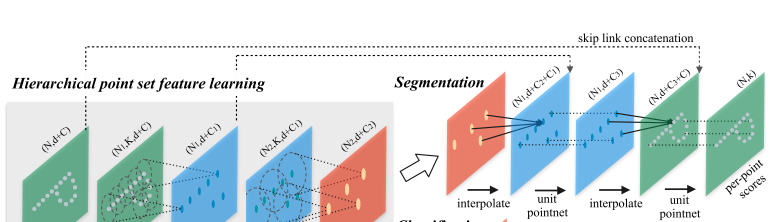
集合分割中的点特征传播
- set abstraction layer中存在点云的下采样,但语义分割时需要每个原始点的label信息
- 方法一:将所有原始点均设置为质心,计算量大
- 方法二:从下采样点传播会原始点
- 基于distance based interpolation和across lavel skip links设计传播
distance based interpolation
- 将点特征从N_l\times (d+C)个点传播至N_{l-1}个点,N_l\le N_{l-1}
- N_{l-1}和N_l为set abstraction level层级l的输入和输出点的个数(点云大小)
- 根据N_{l-1}个点的坐标信息(distance based),将N_l个点的特征值f插值传播
- 选用基于KNN的inverse distance weighted average进行插值
- 实验选择k=3,p=2
f^{(j)}(x)=\frac{\sum_{i=1}^kw_i(x)f_i^{(j)}}{\sum_{i=1}^kw_i(x)}\quad\text{where}\quad w_i(x)=\frac{1}{d(x,x_i)^p},j=1,...,C
across lavel skip links
- 插值得到的N_{l-1}个点的特征同set abstraction层的特征值进行concate
- 组合后的特征传入unit pointnet(类似于1\times 1卷积)
- 使用几个共享的全连接层和ReLu更新每个点的特征
- 迭代进行上述步骤,直到原始点传播完毕
代码学习
说明
- 本文学习的代码为PyTorch版本的,其Github链接如下:
本文是原创文章,采用 CC BY-NC-SA 4.0 协议,完整转载请注明来自 JasonLi